高并发学习笔记
出自b站马士兵的相关教程
1.程序运行的底层原理
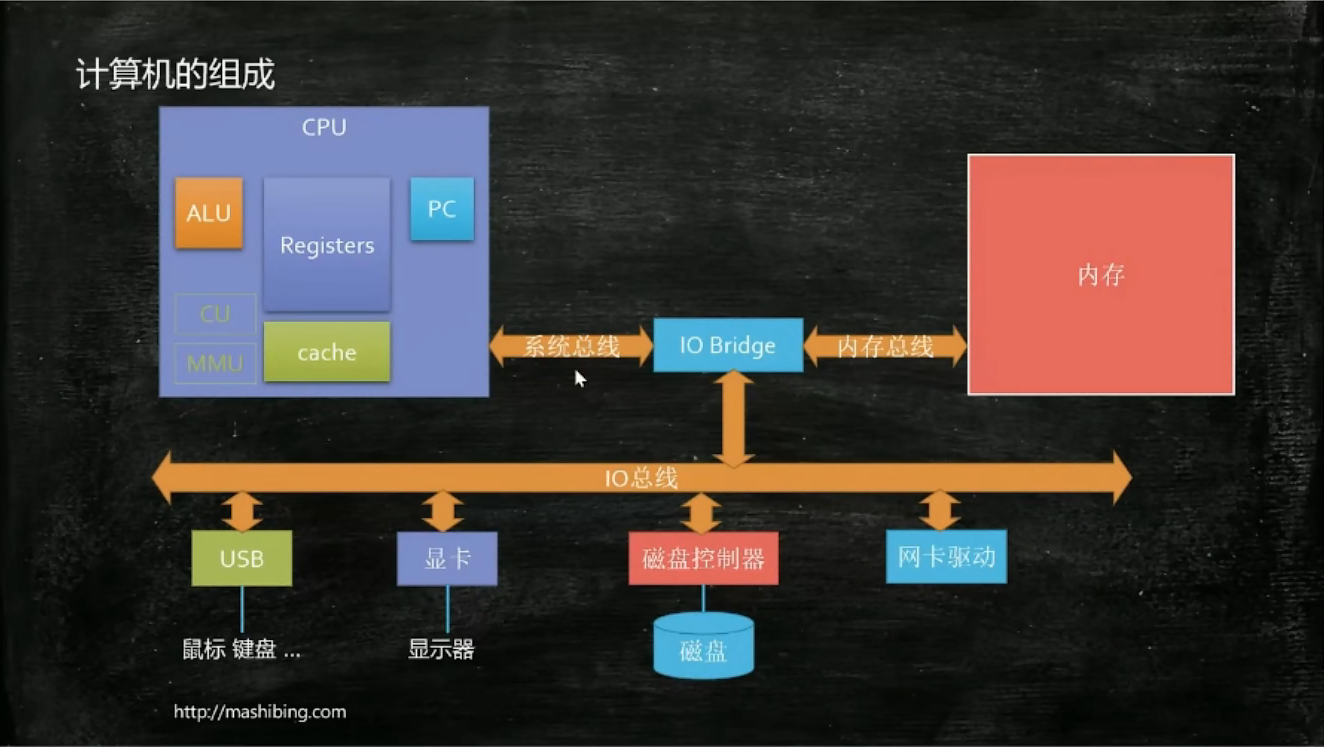
程序是什么? –> XX.exe (躺在磁盘里)
进程是什么? –> “程序启动,进入内存” 资源分配的基本单位(似乎为数据+指令)
线程是什么? –> 程序执行的基本单位
程序如何开始运行? –> CPU读指令:PC存储指令地址、Register读数据、ALU进行数学计算,回写,下一条
程序如何调度?
–> 原始时所有app可以直接操作硬件,为了管控这些app,出现了操作系统。没当某个app产生某个线程,操作系统就会进行线程调度,决定哪个线程放入哪个cpu执行。
但是上方这个调动不是a做完再换b,而是a做一会儿再换b再换回a这样。为了保存上一次操作某个线程的现场,就需要把上次操作的情况存入cache(缓存)。这些叫做线程的切换。
2.CAS(compare and swap)的实现
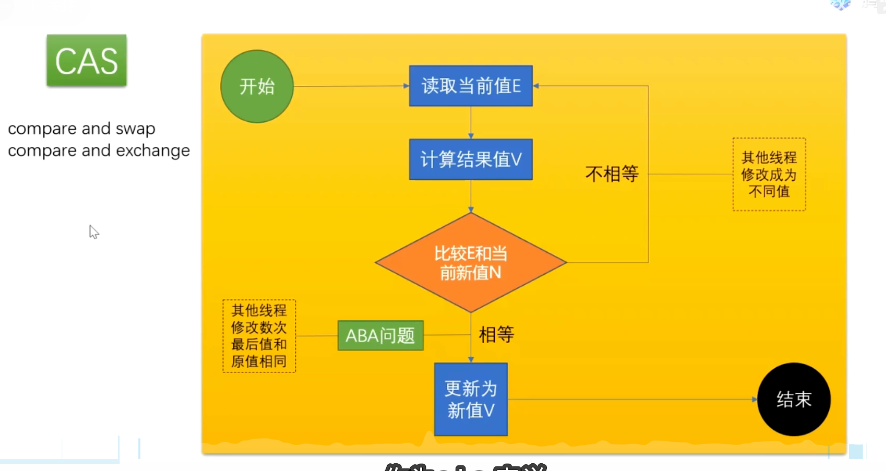
表层逻辑如上图
和sympathizer和volatile一样,底层实现逻辑都是靠lock指令在硬件级别锁定一个北桥芯片。
内存布局:
可以使用openJDK里的工具JOL来直接输出某个对象的内存布局。其maven调用如下:
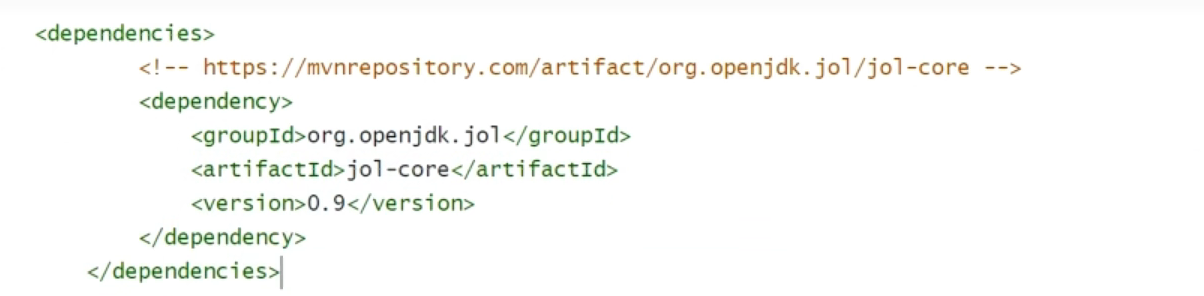
比如要查询一个新创建的Object的布局,查看代码如下:
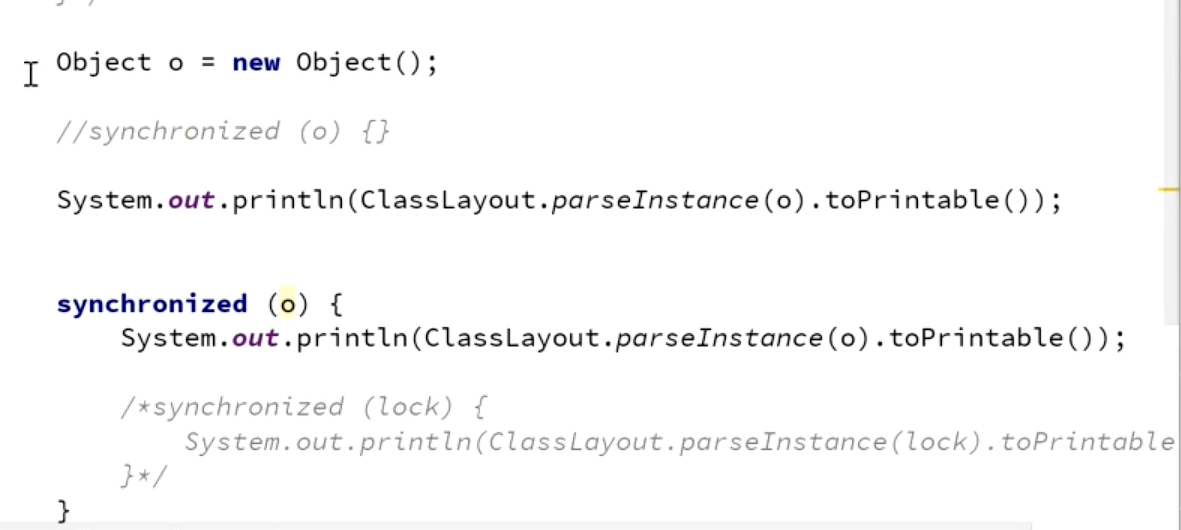
(下面那一行被注释的代码可以输出后发现markword改变,即得锁的信息储存在对象头里,如下图)
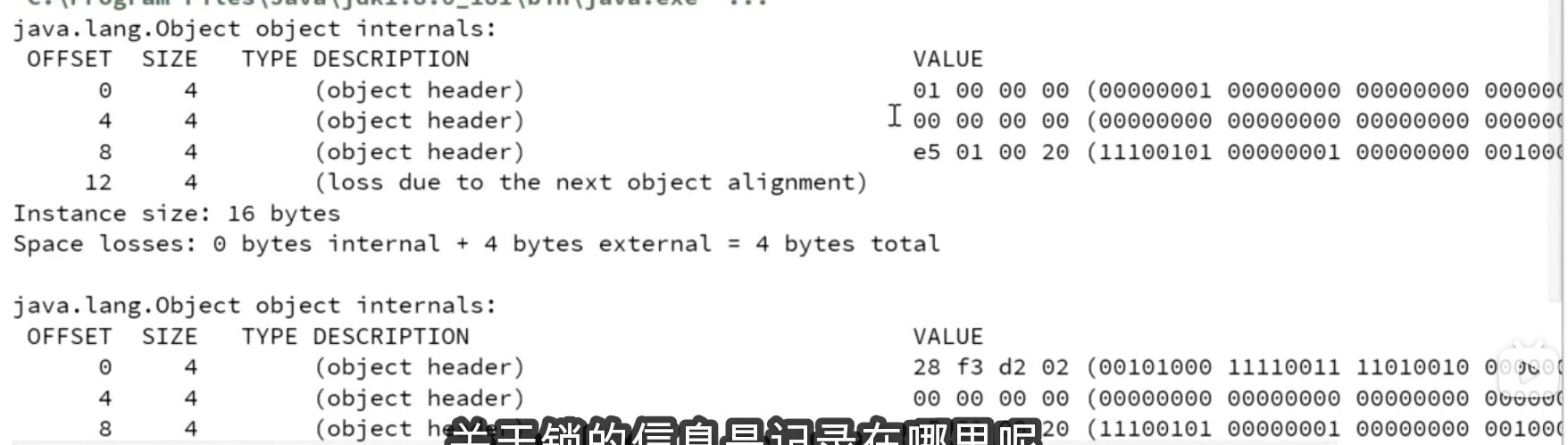
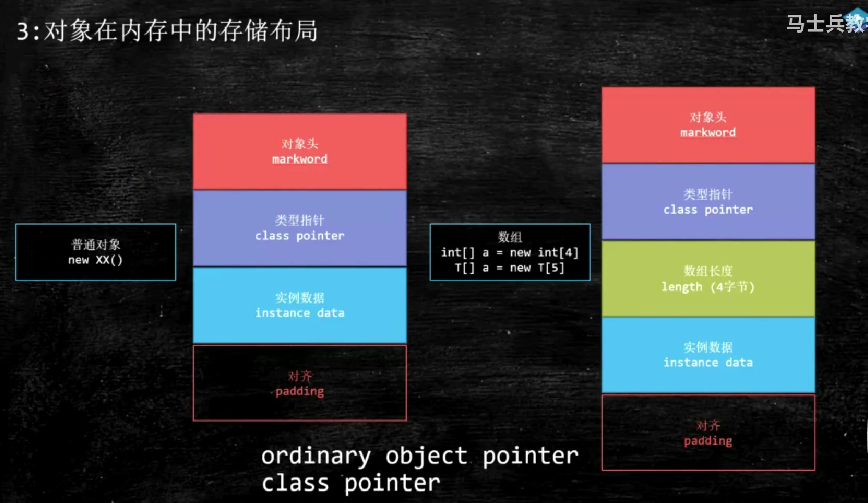
此处可以先了解对象在内存中是这样存储的,如图:
markword大小为8个字节64位,
类型指针本来是8字节,但由于默认的压缩机制,存储时为4字节,
最后会通过加空白让对象的大小为8字节的整数倍。
3.锁升级的过程
锁和GC标记信息都会被存储在对象头markword里,其中锁的种类有下图几种

【ps:上图中有一个hashcode,这东西是用来给对象分类的,方便在使用的过程中查找。同类的对象会有相同的hashcode,在再某堆hashcode相同的对象里通过equals()找到指定的对象。从而提高查找效率】
一个对象刚刚new出来的时候为无锁态。(无锁态和下面的无锁不是一种东西)
当第一个线程使用某个对象时,使用的锁为偏向锁,即标记上该线程自己的标志(指向当前线程的指。针),其他线程发现这个对象时就不会使用。这样就不需要去向操作系统申请重量级锁,从而提升了效率。(这种锁适用于没有发生竞争的时候,即实质上从头到尾只有第一个线程使用了该对象)
当发生了其他线程与第一个线程的竞争时,偏向锁会升级为轻量级锁(又叫自旋锁、无锁)其过程为:撤销之前的偏向锁,原线程和新线程都在自己的线程栈里生成自己的一个对象lock record(LR),两个LR发生争抢,这个争抢是自旋过程:某个线程先读出对象的锁的位置里原来的值,改成一个指向自己LR的指针,再尝试往回写。在回写之前检查那个位置的值是否和之前读的一样,如一样则争抢成功。失败方会反复重复自旋读写的过程,当然在成功者结束前会它还会一直失败。
当某个自旋的锁自旋超过10次或者在自旋等待的锁超过了cpu核数的1/2,则轻量级锁会被升级为重量级锁(这个规则在jdk1.6之后加入了自适应自旋,由jvm自己判断)。
操作系统一般分为用户态和内核态(两者之间互相切换),内核态用来执行大部分那些直接操作硬件的任务,用户态来运行应用程序。当要操作硬件时,由内核代为执行。而锁在内核中是一群有数量限制的互斥的数据结构。只有应用程序等想内核申请使用重量级锁,内核才能给予它们锁,即一个指向重量级锁的指针。
重量级锁内含队列,它可以让之前在自旋的线程们在队列中停止等待(wait或阻塞),从而不再持续消耗cpu。当轮到某个线程时由操作系统指定打开。
锁降级会在一些特定的情况下发生(GC的时候)(Garbage Collection),没什么意义。
关于锁还有两个概念分别叫做逃逸分析和同步省略,同步省略又被叫做锁消除,相关的具体解释可以查看此处:深入理解Java中的逃逸分析。锁粗化的原理作用也差不多,此处不多赘述。
(上面这个链接里还顺便解释了JIT即时编译技术,也就是把热点代码直接翻译成机器语言缓存起来)
2022/8/25 21:49
4.缓存行(cache line)的概念
计算机在读取数据的时候从main mamory -> L3 Cache -> L2 Cache -> L1 Cache 的过程是按块读的,即除了当前需要的数据本身还有其后面的一片,这样就可以避免之后要用到后面数据时反复上方的过程。而这一个块就被成为一个cache line,大小为64字节。
在cpu层级中,为了维持数据的一致性,如果有两个线程同时对同一个cache line里的数据进行了修改,当一个线程发生了修改后,它要通知其他线程这个修改。因此,如果我们使用继承等手段把一个对象的大小刚好凑在(放大到)64字节,使之不可能与其他对象在同一缓存行,修改之时不会互相影响,运行速度反而会变快。这种写法叫做缓存行对齐。有一个框架叫做disruptor(闪电)底层用了这个原理。


